Stupid stunts with WSL2 , Python3 and AWS ECS
Hand rolled CMS system gets a previewer
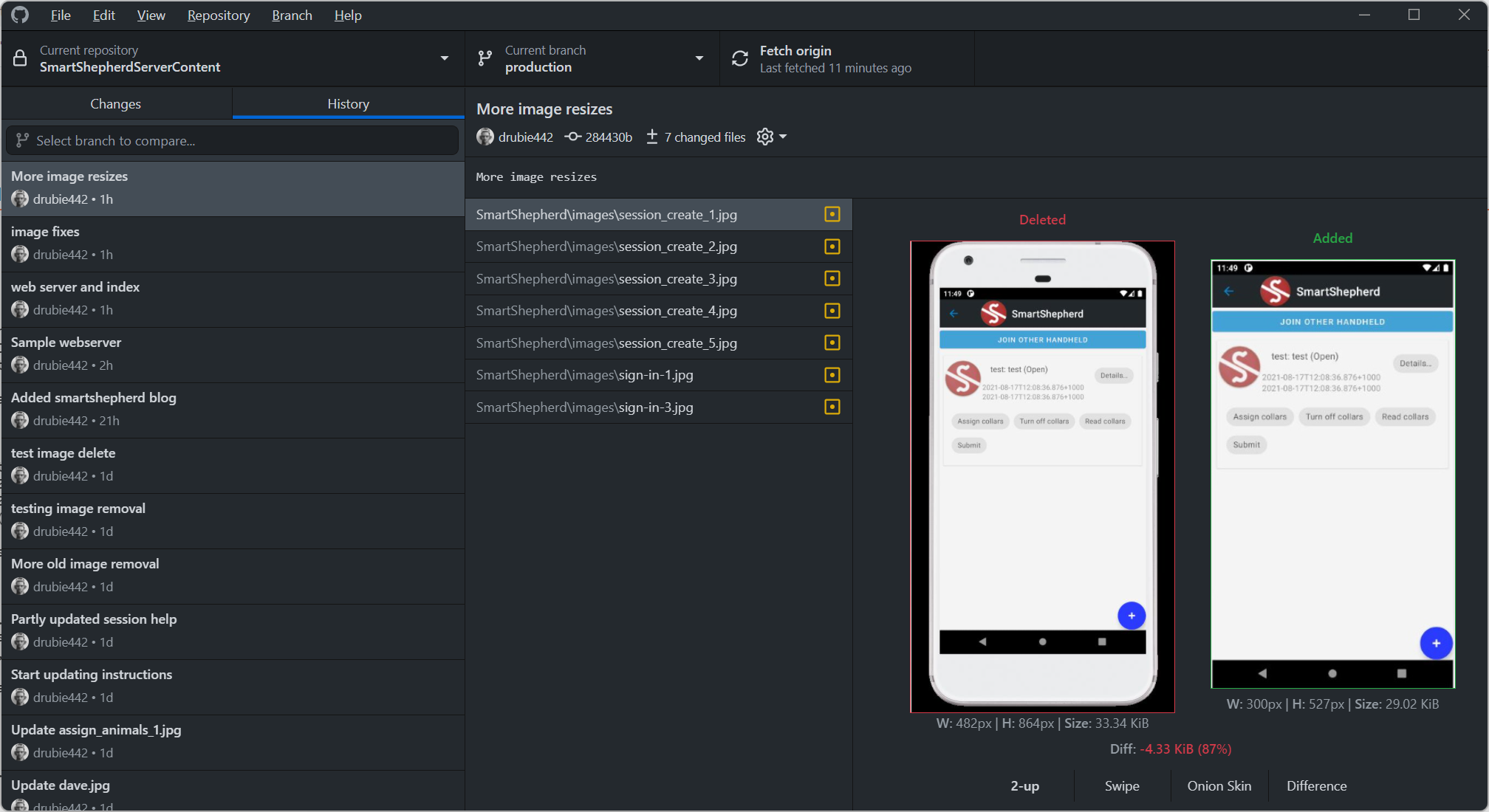
The ongoing process of updating the help system on the SmartShepherd inspired two new features: editing of the html in a temporary location and a small web server to check your work before pushing it to production. The surprise? That GitHub desktop will show you a side-by-side view if you change an image file. Can't believe I didn't notice that before.
Can you hold my camel for me?
Sometimes I get so far down a dead end I don't realise how many issues could be sorted simply by re-thinking something. The initial deployment of the SmartShepherd web server was to an Elastic Beanstalk setup on AWS, mostly because I had no idea what I was doing. Elastic Beanstalk isn't really one product, it's more of an elaborate script that creates systems for you. In my case, it was spinning up a small Windows EC2 instance, installing the .NET Core website and auto-configuring a load balancer to point to that instance. I mean, it's quite clever and it got me running. At the time "got me running" was incredibly important, I had a rapidly expiring and incredibly expensive license for a product called ThingWorx that I was desperate to shed. It was a legacy of the former co-founder of SmartShepherd, originally meant for end users to access but was never good enough for that. In fact it was so poor I ended up building the new server system in the shadows just so I could reliably get results to customers, whom this character didn't want to deal with. Dark times indeed.
Anyway, promoting the shadow system to the main system was something of a high priority so Windows on Elastic Beanstalk it was. When I realised that the cost was double compared to a Linux EC2 instance, I figured why not go the whole hog and containerise the damn thing and be done with it. With ThingWorx a dead roo carcase on the highway at this point, I had nothing to lose.
Visual Studio (the full fat version) has a set of AWS extensions for deploying your container, so once I had the containerising done (which was surprisingly easy), I then had to set about getting ECS working. Long story short, the instructions for ECS fargate at the time kind of skipped over the part where the container gets automatically registered to your load balancer. Who cares, I had the service set up, the task set up, the container was running and accessible, so every time I released a new version of the container I simply went ahead and manually edited the targets for the load balancer.
This gets pretty old when you're deploying new features or fixing bugs. You have to plough through the AWS interface to find your tasks, Ctrl-C the internal IP address of the new container, note the IP address of the old one, register the new one in the target (another exercise in AWS website clicking and hunting), deregister the old one. What a faff.
Occasionally I would google "how do you automatically register an ECS Fargate task with a load balancer target" but nothing would come up. This was a complete mystery to me, although generally if you can't find your problem by searching google you are most likely doing something very wrong. Which I was
I hatched a cunning plan to automatically scrape the IP addresses from the task list and use a convoluted script to register the new targets and de-register the old ones. Lucky I didn't get down that path too far. Simply going back and re-creating the service in AWS, under a new name, had the automatic registering of targets built into the setup. I swear it wasn't there before!
No matter. Now an "dotnet ecs deploy" is all that is needed. No faffing about and bonus: the auto scaler stuff seems to work as well. No need to ask her to hold the camel for you.
Surprise, it's me the bus driver
Python is amazing. I sat down this morning for a couple of hours of Python hacking to create a preview web server for the hand-rolled CMS that is now completely based around GitHub and S3. It took exactly 5 minutes thanks to the kind fellows who answered this question on stackoverflow:
import os
import posixpath
import urllib
import http.server
from http.server import HTTPServer,SimpleHTTPRequestHandler
from urllib.parse import unquote
# modify this to add additional routes
ROUTES = (
# [url_prefix , directory_path]
['/ContentImages', './SmartShepherd/images'], # image directory redirect
['/translations', './SmartShepherd/translations'] # empty string for the 'default' match
)
class RequestHandler(SimpleHTTPRequestHandler):
def translate_path(self, path):
"""translate path given routes"""
# set default root to cwd
root = os.getcwd()
# look up routes and set root directory accordingly
for pattern, rootdir in ROUTES:
if path.startswith(pattern):
# found match!
path = path[len(pattern):] # consume path up to pattern len
root = rootdir
break
# normalize path and prepend root directory
path = path.split('?',1)[0]
path = path.split('#',1)[0]
path = posixpath.normpath(urllib.parse.unquote(path))
words = path.split('/')
words = filter(None, words)
path = root
for word in words:
drive, word = os.path.splitdrive(word)
head, word = os.path.split(word)
if word in (os.curdir, os.pardir):
continue
path = os.path.join(path, word)
return path
if __name__ == '__main__':
myServer = HTTPServer(('0.0.0.0', 8000), RequestHandler)
print("Ready to begin serving files.")
try:
myServer.serve_forever()
except KeyboardInterrupt:
pass
myServer.server_close()
print("Exiting.")
In my case, all I wanted to do was redirect a couple of paths to the stored content in the GitHub directory. There is another script that builds an index.html and voila, I can see the images in context with the content pages. I now have no excuses and will hopefully finish up the help pages updates this week. I have a small set of scripts: editpage.py that takes a copy of the html files to edit, including language variations; updatepage.py that copies the changes back to the CMS structure and updates the reference .json file that holds the metadata; buildindex.py that rebuilds the index.html file for the previewer; check.py that is the script above. Firing up the check.py script, which opens the web server on localhost://8000 needs no fiddling with to be accessable from a windows based browser. WSL2 is quite incredible.
Now, where's that lady with the sore tooth
GitHub Desktop - I have a bit of a love/hate relationship with it. It seems to do odd things with files when (say) you are editing a file in a WSL2 Debian shell that resides on the Windows file system, then head back to a Windows hosted GitHub desktop, the stupid thing will kindly fill out your line endings with the dreaded Carriage Return, so windows editors won't freak out. It's annoying as hell, I'm sure there is a way to stop it from doing that but I'm too lazy today to work out what that is.
However, this is a very cool feature I hadn't noticed before and for me it's incredibly handy for a hand-rolled CMS.